Spark Standalone Cluster Internals
Introduction
This article describes the internal workings of a Spark cluster operating in a standalone mode. The primary motivation is to understand the internal architecture and topology of the Spark cluster execution platform.
I do have experience with building distributed systems using other clustering frameworks like Coherence and Hazelcast.
· The architecture is based on a multicast group, a master and slave nodes. The execution managers in these systems follow a Task execution model operating on an in memory distributed key-value data structure [a Concurrent Hashmap].
· Tasks or Entry Processors are the basic unit of execution.
· These managers provide guarantees like fault-tolerance, distribution of data based on partitioning schemes like hash partitioning and restoring the execution from a faulty node. [This is obtained by maintaining a state machine and reconstructing a new JVM by loading the failed partition-Id from a backup partition, upon a failure event].
When I moved to Spark, I read about similar guarantees. After watching a few presentations and reading the original whitepaper, I realized that Spark’s internal architecture is very different and primarily the execution sequence is maintained by a DAG [Directed acyclic graph] and the state can be reconstructed from this lineage. There are many articles and videos that explain all of this in detail.
There were many technical terms like Master, Worker, Executor JVM, Tasks, Threads and Partitions. Though I understood this at a theoretical level, I could not get a good grasp of the internals. Also, what is the basic unit of execution? After a few troubleshooting and debugging sessions, I began to understand these semantics and also realized that UDF’s [User defined functions] or lambda’s are the basic unit of execution. The client application is written as a sequential program.
The sections below walk through the basic steps of Setup of a Standalone Spark Cluster, submission of a task and retrieving the results back on to the client program. These steps have been outline in the excellent text à “Learning Spark.”
This article expands on the same providing more insights and explains finer points at the implementation level.
Command to launch the Master JVM:

A true distributed setup would be on different physical machines. That requires setting up ssh keys on master and worker nodes.
In this document, the master and the worker node is configured on the same machine. The machine has 12 CPU cores.
Source code for Spark -2.2.0 has been cloned from the Spark Git Repo.
Command to launch the Master JVM:
root@ubuntu:/home/customer/spark-2.2.0-bin-hadoop2.7/bin#
./spark-class -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8787 org.apache.spark.deploy.master.Master
The shell script spark-class is used to launch the master manually. The first args are JVM args launching
the master in debug mode. The JVM is suspended and waits for the IDE to make a remote connection.
Following are the screenshots showing the IDE configuration for Remote Debugging:
the master in debug mode. The JVM is suspended and waits for the IDE to make a remote connection.
Following are the screenshots showing the IDE configuration for Remote Debugging:
Launch the master and observe in the debugger.
One of the first step is to elect the leader.

The Code is seen in Master.scala:

Few important log messages from the master:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/12/29 20:26:07 INFO Master: Started daemon with process name: 22202@ubuntu
17/12/29 20:26:07 INFO SignalUtils: Registered signal handler for TERM
17/12/29 20:26:07 INFO SignalUtils: Registered signal handler for HUP
17/12/29 20:26:07 INFO SignalUtils: Registered signal handler for INT
17/12/29 20:26:07 WARN Utils: Your hostname, ubuntu resolves to a loopback address: 127.0.1.1; using 10.71.220.34 instead (on interface em1)
17/12/29 20:26:07 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
17/12/29 20:26:07 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/12/29 20:26:07 INFO SecurityManager: Changing view acls to: root
17/12/29 20:26:07 INFO SecurityManager: Changing modify acls to: root
17/12/29 20:26:07 INFO SecurityManager: Changing view acls groups to:
17/12/29 20:26:07 INFO SecurityManager: Changing modify acls groups to:
17/12/29 20:26:07 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
17/12/29 20:26:08 INFO Utils: Successfully started service 'sparkMaster' on port 7077.
17/12/29 20:26:08 INFO Master: Starting Spark master at spark://10.71.220.34:7077
17/12/29 20:26:08 INFO Master: Running Spark version 2.2.0
17/12/29 20:26:08 INFO Utils: Successfully started service 'MasterUI' on port 8080.
17/12/29 20:26:08 INFO MasterWebUI: Bound MasterWebUI to 0.0.0.0, and started at http://10.71.220.34:8080
17/12/29 20:26:08 INFO Utils: Successfully started service on port 6066.
17/12/29 20:26:08 INFO StandaloneRestServer: Started REST server for submitting applications on port 6066
17/12/29 20:26:42 INFO Master: I have been elected leader! New state: ALIVE
Command to launch the Worker JVM:
root@ubuntu:/home/customer/spark-2.2.0-bin-hadoop2.7/bin# ./spark-class -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8788 org.apache.spark.deploy.worker.
Worker spark://10.71.220.34:7077
Worker spark://10.71.220.34:7077
Same as master, the last argument specifies the address of the spark master . This is where the RPC server
for the master is running. The debug port for master is 8788.
for the master is running. The debug port for master is 8788.
As part of the launch the worker registers with the master.
Screenshot

The logs from the master node confirm the registration:
17/12/29 20:34:24 INFO Master: Registering worker 10.71.220.34:36528 with 12 cores, 30.3 GB RAM
Logs from the worker node:
17/12/29 20:34:09 INFO Worker: Starting Spark worker 10.71.220.34:36528 with 12 cores, 30.3 GB RAM
17/12/29 20:34:09 INFO Worker: Running Spark version 2.2.0
17/12/29 20:34:09 INFO Worker: Spark home: /home/customer/spark-2.2.0-bin-hadoop2.7
17/12/29 20:34:09 INFO Utils: Successfully started service 'WorkerUI' on port 8081.
17/12/29 20:34:09 INFO WorkerWebUI: Bound WorkerWebUI to 0.0.0.0, and started at http://10.71.220.34:8081
17/12/29 20:34:09 INFO Worker: Connecting to master 10.71.220.34:7077...
17/12/29 20:34:18 INFO Worker: Retrying connection to master (attempt # 1)
17/12/29 20:34:24 INFO Worker: Connecting to master 10.71.220.34:7077...
17/12/29 20:34:24 INFO TransportClientFactory: Successfully created connection to /10.71.220.34:7077 after 45 ms (0 ms spent in bootstraps)
17/12/29 20:34:24 INFO Worker: Successfully registered with master spark://10.71.220.34:7077
Screen shot from the system monitor [gnome-system-monitor] showing the launch of the worker.

A Basic java app with a main method is compiled and wrapped in an uber/fat jar. This has been explained in the text “learning spark”. Basically an Uber jar contains all transitive dependencies.
Created by running mvn package at the following directory:
root@ubuntu:/home/customer/Documents/Texts/Spark/learning-spark-master# mvn package
The above generates a jar under ./target folder
The screen shot below is the java application, which would be submitted to the Spark Cluster:

Command to submit the command to the standalone cluster
root@ubuntu:/home/customer/Documents/Texts/Spark/learning-spark-master# /home/customer/spark-2.2.0-bin-hadoop2.7/bin/spark-submit --master spark://10.71.220.34:7077
--conf "spark.executor.extraJavaOptions=-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8790"
--conf "spark.executor.extraJavaOptions=-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8790"
--conf "spark.executor.extraClassPath=/home/customer/Documents/Texts/Spark/
learning-spark-master/target/java-0.0.2.jar" --class com.oreilly.learningsparkexamples.java.BasicMapToDouble
learning-spark-master/target/java-0.0.2.jar" --class com.oreilly.learningsparkexamples.java.BasicMapToDouble
--name "MapToDouble"
./target/java-0.0.2.jar
spark://10.71.220.34:7077 → Argument to the java program → com.oreilly.learningsparkexamples.java.BasicMapToDouble
· The above command is from the client node that runs the application with the main method
in it. However the transformations are executed on the remote executor JVM.
in it. However the transformations are executed on the remote executor JVM.
· The –conf parameters are important. They are used to configure the executor JVM's.
The Executor JVMS are launched at runtime by the Worker JVM's.
The Executor JVMS are launched at runtime by the Worker JVM's.
· The first conf parameter specifies that the Executor JVM should be launched in debug
mode and suspended right away. It comes up on port 8790.
mode and suspended right away. It comes up on port 8790.
· The second conf parameter specifies that the executor class path should contain the
application specific jars that are submitted to the executor. On a distributed setup these jars
need to be moved to the Executor JVM machine.
application specific jars that are submitted to the executor. On a distributed setup these jars
need to be moved to the Executor JVM machine.
· The last argument is used by the client app to connect to the spark master.
To understand, how the client application connects to the Spark cluster,
we need to debug the client app and step through it. For that we need to configure it to run
in the debug mode.
Contents from the spark-submit
exec "${SPARK_HOME}"/bin/spark-class -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8789 org.apache.spark.deploy.SparkSubmit "$@"
As the first step the client app builds a SparkContext.
JavaSparkContext sc = new JavaSparkContext(
master, "basicmaptodouble", System.getenv("SPARK_HOME"), System.getenv("JARS"))
This sends a registration with the master node. The master node instructs the worker to start an executor:
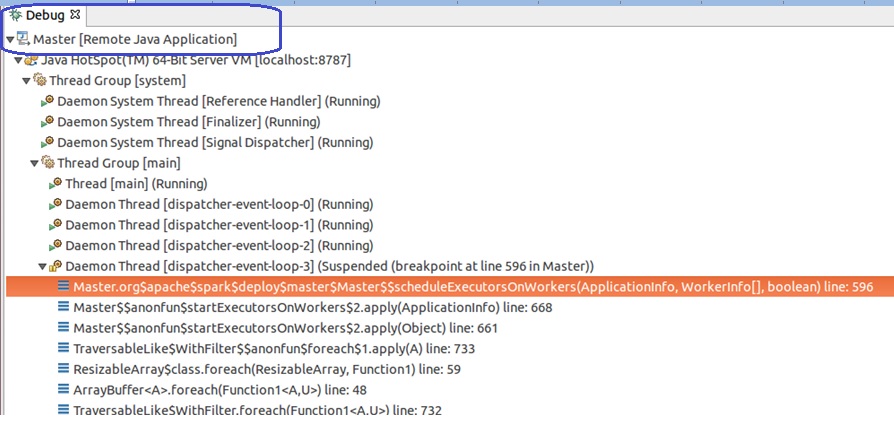

The worker starts an executor at run-time on a different thread.
Screenshot below shows the class ExecutorRunner.scala


The screenshot below shows, the daemon thread that builds the command line for the executor and
launches the executor:

System monitor View [Launched by running command: gnome-system-monitor] showing the new java executor process forked by the worker. Select the option “view dependencies” to view the process tree/hierarchy.

The Worker JVM blocks at the following call:
ExecutorRunner.scala
// Wait for it to exit; executor may exit with code 0 (when driver instructs it to shutdown)
// or with nonzero exit code
val exitCode = process.waitFor() → BLOCKING CALL
state = ExecutorState.EXITED
val message = "Command exited with code " + exitCode
worker.send(ExecutorStateChanged(appId, execId, state, Some(message), Some(exitCode)))
We now connect to the forked executor JVM using the IDE. Executor JVM would run the
transformation functions in our submitted application.
JavaDoubleRDD result = rdd.mapToDouble( → Transformation function/lambda
new DoubleFunction<Integer>() {
public double call(Integer x) {
double y = (double) x;
return y * y;
}
});
However, the transformation function runs, only when the action “collect” will be invoked.
System.out.println(StringUtils.join(result.collect(), ","));
The screenshot below displays the Executor view, when the mapToDouble function is invoked in parallel
on multiple elements of the list. The Executor JVM executes the function in 12 threads as there are 12
cores. As the number of Cores was not set on the command line, the worker JVM by default set
the option: -cores=12.
on multiple elements of the list. The Executor JVM executes the function in 12 threads as there are 12
cores. As the number of Cores was not set on the command line, the worker JVM by default set
the option: -cores=12.


The key class that runs the task is:
org.apache.spark.scheduler.ResultTask[T, U].runTask(context: TaskContext)
override def runTask(context: TaskContext): U = {
// Deserialize the RDD and the func using the broadcast variables.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
func(context, rdd.iterator(partition, context))
}
Screen shot showing the client submitted code [maptodouble()]
running in the remote forked Executor JVM.


After all the tasks have been executed, the Executor JVM exits. After the client app exits, the
worker node gets unblocked and waits for the next submission.
worker node gets unblocked and waits for the next submission.
Spark Local Mode
This mode executes the functions on the client JVM.
Command to run the tasks on the client JVM node as part of the client application.
/home/customer/spark-2.2.0-bin-hadoop2.7/bin/spark-submit --master spark://10.71.220.34:7077 --conf "spark.executor.extraClassPath=/home/customer/Documents/Texts/Spark/learning-spark-master/target/java-0.0.2.jar" --class com.oreilly.learningsparkexamples.java.BasicMapToDouble --name "MapToDouble" ./target/java-0.0.2.jar local[*]
The last argument ensures that the task is run in parallel with exact number of threads corresponding to the number of the cores.
References
https://spark.apache.org/docs/latest/configuration.html → for the setting the runtime executor conf arguments
Nice Article, explaining the internal of master and worker code execution using debug option! Looking forward for more :)
ReplyDeleteSandeep, this is very useful for any one who is trying to explore Spark. thanks a lot for contributing.
ReplyDelete